Q1. Please breifly discuss Hashmap in JDK 1.8
Hashmap is a map interface based on hash table implementation. This implementation provides all optional mapping operations and allows empty values (value) and empty keys (key). (The HashMap class is roughly equivalent to Hashtable, but it is thread-unsafe and allows null values) This class cannot guarantee the order of mapping; in particular, it cannot guarantee that the order remains the same over time.
Q2. Please discuss the underlying structure of Hashmap in JDK 1.8
The bottom layer of hashmap is implemented by arrays and linked lists (when the length of the linked list in jdk1.8 is greater than 8, the linked list will be converted into a red-black tree)
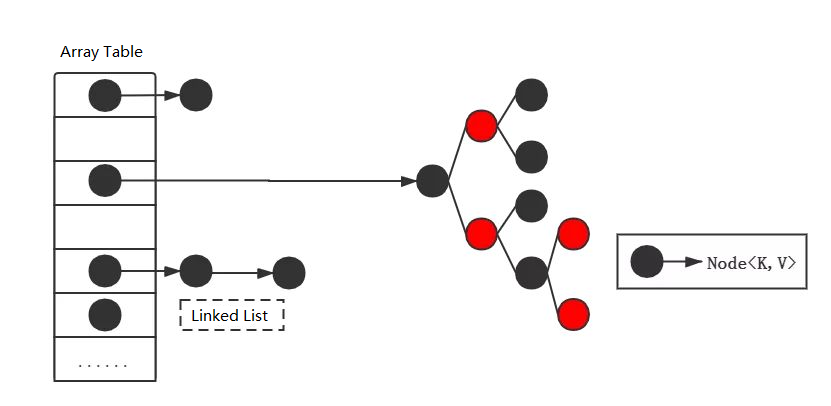
Q3. Initial capacity and maximum capacity of Hashmap
The initial capacity of Hashmap in JDK 1.8 is 16.
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
The maximum capacity of Hashmap in JDK 1.8 is 1 << 30. It is not 1 << 31, since the leftmost bit represents the sign bit, and the capacity cannot be a negative number
static final int MAXIMUM_CAPACITY = 1 << 30;
Q4. Why the prescribed capacity must be 2 to the power of n?
- Speed up hash calculation
- Evenly distribute data, reduce hash conflicts
// Calculate the index
i = (len - 1) & hash
len is the length of the array.Since len is 2 to the nth power, (n-1) is converted to binary base and all become 1.
The n-th power of 2 can be realized by displacement operation, which can speed up the hash calculation speed and speed up the calculation of array subscripts in combination with bitwise and calculation. For example, when expanding the HashMap, satisfying the power of 2 is equivalent to doubling every time the expansion is performed (i.e., <<1 is shifted to the right by one bit), so when recalculating the subscript position during expansion, there are only two cases, one The subscript is unchanged. The other is that the subscript becomes: original subscript position + capacity before expansion so that the nodes move relatively less after expansion, and performance can also be improved.
It can improve the uniform distribution of data and reduce hash conflicts. After all, the larger the hash conflict, the larger the length of a chain in the array, which will reduce the performance of the hashmap.
The key code is the array subscript calculation in HashMap: i = (n-1) & hash. This calculation method can achieve a uniform distribution.
Q5. How hashmap calculates the hash value?
XOR between the first 16 bits and the last 16 bits
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
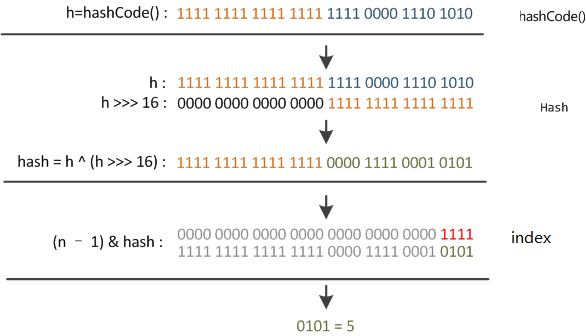
In order to solve the hash collision problem, both the high and low bits participate in the calculation of the hash value.