Redis brief introduction
Redis is a key-value database written in c language, open-source, and highly available non-relational database (NoSQL, not just database) type.
Unlike traditional databases, Redis data exists in memory, so the read and write performance is not generally high, and can reach 100,000 operations per second, so it is widely used in the cache direction, for example: in the website architecture and tomcat Do session sharing, do database caching, etc.
Pros and cons of Redis
Pros:
- Fast read and write speed, read can reach 110,000 times/s, write can reach 81000 times/s, written in C language, the code is elegant, and it is also single-threaded architecture, so the execution efficiency is high, and the speed is fast.
- Support multiple data structures: String (string, is also the most commonly used), hash (hash), list (list), set (SET), ordered set (ZSET)
- Rich functions, such as natural counter, key expiration function, message queue, etc.
- Support many client languages, support PHP, Java, Python
- Support data persistence
- Comes with a variety of high-availability architectures, such as master-slave replication, sentinels, and high-availability clusters
Cons:
- The data is fragile since it is stored in the memory, so the server performance requirements are strict, according to the business volume, choose appropriate memory size, which is financially costly.
- It is difficult to achieve online expansion, so the first purchase needs to be cautious.
What is data persistence?
Persistence is to support writing the data in the memory to the disk to prevent all data in the memory from being lost when the server is down.
Methods to achieve data persistence
Redis supports 2 formats of persistent data, namely AOF, RDB, and the mixed-use of AOF&RDB.
When the mixed-use turned on, Redis data recovery prefers to use AOF, but RDB is the default persistence method.
AOF persistence: It is to record every command executed by Redis in a separately specified log file, and the data in the log file will be restored when the data is restarted or when data is to be restored.
RDB persistence: Just like taking a snapshot, the snapshot period is defined according to the save parameter defined in the configuration file, and then saved to the hard disk, a dump.rdb file will be generated.
Comparison of AOF and RDB
How to choose an appropriate data persistence method?
- AOF files are updated more frequently than RDB. AOF is preferred to restore.
- AOF is safer than RDB
- RDB performance is better than AOF, when the amount of data is large, the log recovery speed is slower than RDB.
- During continuous reading and writing, if the RDB takes a snapshot, there will be data delays and the recovered data will be incomplete.
Redis data persistene tutorial
Deploy Redis
- Create a folder to store data
mkdir -p /redis/soft
mkdir -p /opt/redis_cluster/redis/{conf,logs,pid}
2. Download Redis installation package and install Redis
Add a soft link for ease of management.
cd /redis/soft
wget http://download.redis.io/releases/redis-5.0.6.tar.gz
tar zxf redis-5.0.6.tar.gz -C /opt/redis_cluster/
ln -s /opt/redis_cluster/redis-5.0.6 /opt/redis_cluster/redis
cd /opt/redis_cluster/redis
make && make install
3. Edit Redis configurations /opt/redis_cluster/redis_6379/conf/6379.conf
bind 127.0.0.1 192.168.10.1
port 6379
daemonize yes
pidfile /opt/redis_cluster/redis_6379/pid/redis_6379.pid
logfile /opt/redis_cluster/redis_6379/logs/redis_6379.log
databases 16
dbfilename redis.rdb
dir /opt/redis_cluster/redis_6379 # data folder
4. Start the Redis service with the given configuration file
redis-server /opt/redis_cluster/redis_6379/conf/6379.conf
[root@redis-master ~]# netstat -anpt |grep 6379
tcp 0 0 192.168.10.1:6379 0.0.0.0:* LISTEN 49206/redis-server
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 49206/redis-server
tcp 0 0 127.0.0.1:41400 127.0.0.1:6379 TIME_WAIT -
tcp 0 0 192.168.10.1:6379 192.168.10.8:46220 ESTABLISHED 49206/redis-server
[root@redis-master ~]#
5. Edit configurations regarding the data persistence
vim /opt/redis_cluster/redis_6379/conf/6379.conf
# add the following lines
save 900 1
save 300 10
save 60 500
6. AOF data persistence
vim /opt/redis_cluster/redis_6379/conf/6379.conf
add the following lines
appendonly yes
appendfilename “redis.aof”
appendfsync everysec
Restart Redis
redis-cli shutdown
redis-server /opt/redis_cluster/redis_6379/conf/6379.conf
Redis master-slave replication
To solve the single point of failure, the data is copied to one or more replica servers (slave servers), to achieve redundancy, and to achieve the purpose of fault recovery and load balancing.
cd /opt/redis_cluster/redis
vim /opt/redis_cluster/redis_6379/conf/6379.conf
#Modify as follows
# bind 127.0.0.1 192.168.10.8
# slaveof 192.168.10.1 6379 # master ip and port
Restart Redis
redis-server /opt/redis_cluster/redis_6379/conf/6379.conf
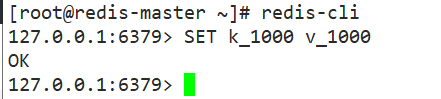
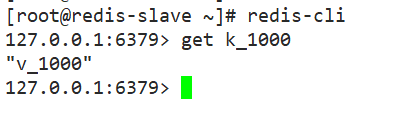
Note:
During the synchronization process, the slave server can only copy the master database’s data and cannot manually add and modify data;
If you want to change the data from the server, you need to disconnect the synchronization:
[root@redis-slave ~]# redis-cli slaveof no one
Prompt confirmation
If the master is down, the slave server can manually disconnect the synchronization first. At this time, he is an independent individual, and the other slave servers point to themselves to complete the switch.