Q11: Discuss HashMap resizing in JDK 1.8
When putting an item, if the map finds that the current bucket occupancy has exceeded the proportion specified by the Load Factor, then a resize will occur. The resizing process simply means expanding the bucket to twice its original size, then recalculating the index and putting the nodes in the new bucket. The resize comment is described as follows: When the limit is exceeded, it will resize, but because we are using the power of 2 expansions (referring to the length of the original two times), the position of the element is either in the original position or Move the position to the power of 2 in the original position.
For example, when the map expands its size from 16 to 32, the specific changes are as follows:
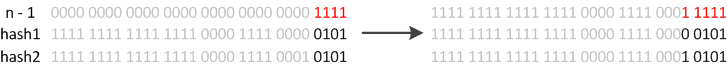
Therefore, after the element recalculates the hash because n is doubled, the mask range of n-1 is 1 bit (red) higher, so the new index will change like this:
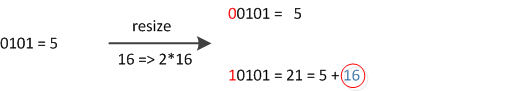
Therefore, when we expand the HashMap, we don’t need to recalculate the hash. We need to see if the bit added by the original hash value is 1 or 0. If it is 0, the index has not changed. If it is 1, the index becomes “Original index + oldCap.” You can take a look at the resize diagram of 16 expanded to 32 in the figure below:
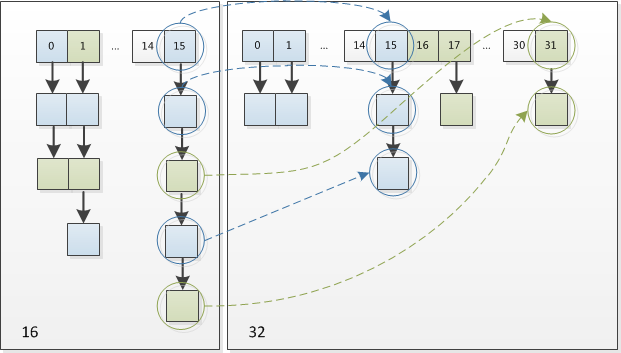
This design is indeed very clever. It not only saves the time to recalculate the hash value, and at the same time because the newly added 1-bit is 0 or 1, which can be considered as a random value. Therefore the resizing process of HashMap evenly disperses the previous conflicting nodes to the new bucket.
Q12: Describe/write the algorithm for HashMap resizing
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
Q13: Describe the principles of GET and PUT in HashMap? What about equals() and hashCode() ?
By hashing the key using hashCode(), and calculating the subscript (n-1 & hash), the location of the buckets can be obtained. If there is a collision, use the key.equals() method to find the corresponding node in the linked list or tree.
Q14: Discuss the difference between head and tail insert in a linked list
JDK 1.7 uses the head interpolation method to insert elements into the singly linked list, and jdk1.8 uses the tail interpolation method.
JDK 1.7 is inserted into the head of the linked list. There is a view that the newly inserted data is more likely to be queried, and inserted into the head to query relatively fast. However, expansion in a multi-threaded environment may cause a circular linked list, resulting in 100% CPU
jdk1.8 improvement: the tail interpolation method is adopted, and the hash value does not need to be recalculated during expansion, and the transformation of the element index value is regular.
Q15: In which cases do we override equals() and hashCode() ?
- hashCode() determines the position of Node/Entry in the array
- equals() is used when elements collide
- By default, hashmap uses java.lang.Object#equals to compare the address of the object. The address is definitely different in the hashmap object storage heap, so you must implement your own equals according to the business, but equals judges the need, but the hashmap judges the hashCode first. Only after equals will equals be executed.
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))
//do something here
public class Name {
private String first; //first name
private String last; //last name
public String getFirst() {
return first;
}
public void setFirst(String first) {
this.first = first;
}
public String getLast() {
return last;
}
public void setLast(String last) {
this.last = last;
}
public Name(String first, String last) {
this.first = first;
this.last = last;
}
@Override
public boolean equals(Object object) {
System.out.println("equals is running...");
Name name = (Name) object;
return first.equals(name.getFirst()) && last.equals(name.getLast());
}
public static void main(String[] args) {
Map<Name, String> map = new HashMap<Name, String>();
Name n1 = new Name("mali", "sb");
System.out.println("the hashCode of n1 : " + n1.hashCode());
map.put(n1, "yes");
Name n2 = new Name("mali", "sb");
System.out.println("the hashCode of n2 : " + n2.hashCode());
System.out.println("is the key existed? ture or false? -> "
+ map.containsKey(n2));
}
}